Pandas 개요
2024. 9. 20. 14:49ㆍ파이썬-머신러닝
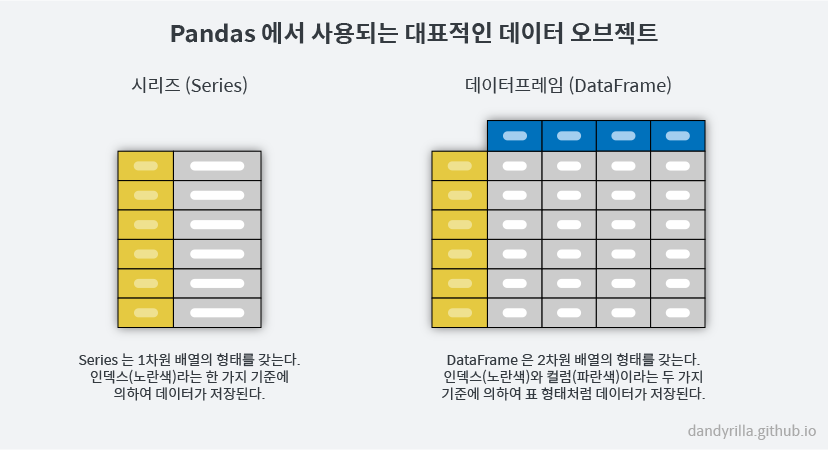
ML에서 Pandas의 핵심: Series, DataFrame
pd.read_csv()
df = pd.read_csv('data/train.csv')- 경로에 있는 파일읽기
- 현재 작업위치에서 data폴더 안의 train.csv 파일을 불러옴
구분자 설정
df = pd.read_csv('data/train.tsv', sep='\t')
- tab으로 구분된 아이는 set 파라미터를 이용해 불러올 수 있음
- 데이터에 따라 구분자(separator)가 매우 다양한데, 제대로 안읽혀도 separator를 변경하면 됨
df.head(n)
- 윗 n줄 출력
- default=5

df.head()
df.dtypes
각 column별 dtype 파악
df.dtypesPassengerId int64 Survived int64 Pclass int64 Name object Sex object Age float64 SibSp int64 Parch int64 Ticket object Fare float64 Cabin object Embarked object dtype: object
df.shape
DataFrame의 (row수, column수)
df.shape(891, 12)
df[col_name]
- column을 시리즈로 불러옴
df['Pclass']0 3
1 1
2 3
3 1
4 3
..
886 2
887 1
888 3
889 1
890 3
Name: Pclass, Length: 891, dtype: int64type(df['Pclass'])하나의 컬럼만 선택하면 시리즈로 나옴
pandas.core.series.Seriesdf.info()
- 칼럼별 칼럼명, null이 아닌 row수, dtype 를 반환
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
df.describe()
- 수치형 데이터 칼럼의 통계량(분위수, 평균, 표준편차, 개수 등)
df.describe()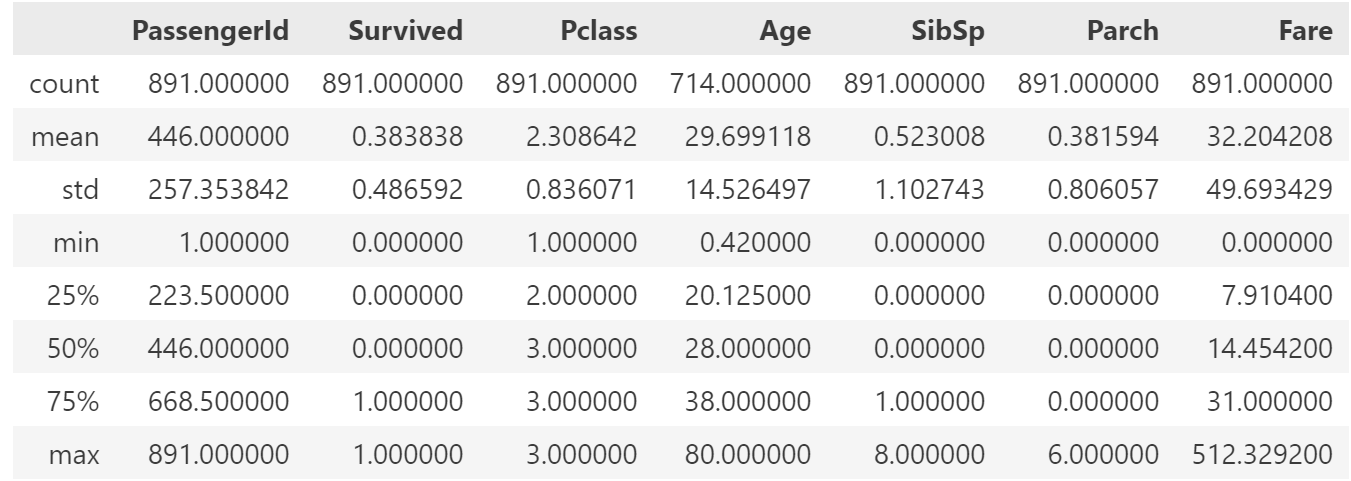
df[col].unique()
- col에 존재하는 고유값들
df['Parch'].unique()array([0, 1, 2, 5, 3, 4, 6], dtype=int64)df[col].value_counts()
- col에 존재하는 값들의 수
df['Parch'].value_counts()Parch
0 678
1 118
2 80
5 5
3 5
4 4
6 1
Name: count, dtype: int64array, list 를 DF로
a = [['Kim','183cm','75kg'],['Lee','178cm','70kg'],['Park','163cm','57kg'],['Choi','168cm','61kg']]
b = np.array(a)
barray([['Kim', '183cm', '75kg'],
['Lee', '178cm', '70kg'],
['Park', '163cm', '57kg'],
['Choi', '168cm', '61kg']], dtype='<U5')df_a = pd.DataFrame(a)
df_b = pd.DataFrame(b)DF를 array로
df_b.valuesarray([['Kim', '183cm', '75kg'],
['Lee', '178cm', '70kg'],
['Park', '163cm', '57kg'],
['Choi', '168cm', '61kg']], dtype=object)array를 list로
df_a.values.tolist()[['Kim', '183cm', '75kg'],
['Lee', '178cm', '70kg'],
['Park', '163cm', '57kg'],
['Choi', '168cm', '61kg']]